Note: there are more configurations than pure lines, pure matrices and pure cubes. The idea here is to get the reader thinking about processing large problems with a divide and conquer type methodology. A key point to visualizing this divide and conquer approach is to see how the compute resources will be created and the data distributed in an aggregated system. So in this system, I will use point, line, plane and cube to represent increasing levels of aggregation in the compute fabric.
In this article I will try to show the relationship between the shape of the fabric of resources that defines a compute engine and that data that feeds this engine. We will talk about establishing well defined paths for data so that it can be partitioned and assigned to specific sets of compute resources.
By sending data to specific resources, some problems with synchronization can be avoided, and the results generated by set of distributed compute resources can be guaranteed to be in sync. This is to say a compute resource does not need to multitask between two time slices at once. Also, a set of related compute resources should follow the same rule; as a group they don't work on more than one data set a time.
One of the key points here is that how compute resources should be arranged and how data should be provided to the arranged resources should be handled AT THE SYSTEM LEVEL. This should not be a function of the individual service, each service should only focus only on input and output not how to participate in a larger distributed picture. It should be blissfully unaware of any distributed nature in the problem. This is the job of the compute engine. By shifting the need to synchronize between versions of data to the compute engine, the code for each component in the system becomes simpler.
See: https://jmenke.blogspot.com/2020/01/the-impact-of-envoy-and-path-to-type.html
This is the idea behind the multiverse of compute.

Aggregated Stream Form - what the data set looks like when viewed in its entirety.
A point transforms to a line in its aggregated stream form. A line is a stream of points.
A line goes to a plane in its aggregated stream form. A plane is a stream of lines.
A plane goes to a cube in its aggregated stream form. A cube is a stream of planes.
From the resource perspective there are dimensions also
A point is a simple one container calculation. 0 dimensions
A line is series of containers processing a calculation. 1 dimension (array)
A plane is series of different types of containers processing a calculation (2 dimensional array)
So stream data for a 0 dimension compute instances is a line of data points (stream) that gets sliced and handed to replicated instances as a single data set per snapshot.
Stream data for a 1 dimensional line of compute resources is a plane (2 dimensional array) of data points (stream) that gets sliced and handed to replicated instances as an array of data sets (1D) per snapshot.
Stream data for a 2 dimensional plane of compute resources is a cube (3 dimensions) of data points (stream) that gets sliced and handed to replicated instances as a matrix of data sets (2D)
The base engine should process all 3 with the same mechanisms. It should be able to time slice data for lines in the same way it time slices planes and cubes.
The implementation of data distribution is a little different than having a central database with the workers querying that central store for their segmented data. The idea here is to optimize data access at the system level by pushing data to local partitioned data stores. This positions data as physically close to the compute as possible.
See https://jmenke.blogspot.com/2019/11/3-dsls-resource-execution-data.html
I am hoping that explaining it this way helps you visualize the data flowing to the correct container in the instance configuration.

The engine should be able to scale out to any number of instances. The familiar recycle logo illustrates reusing instances for new snapshots. As new snapshots of data enter the engine they are passed to an available recycled instance. Once one calculation is done, the instance becomes ready for the next.
Looking at individual sets of data and the containers representing them as 0D, 1D, 2D structures helps to see how data is grouped into a stream and then sent to various configurations for computation.
You may just need 1 container that has a few copies to process a stream of data.
Or you may need a whole set of containers that work homogeneously to partition a problem. When replicated this structure you end up with a plane (2D) of compute resources.
Maybe your problem is even more complex and you need multiple types of containers and your base structure is a plane of compute resources, then the replicated structure is a cube of compute resources.
The main idea here is that there are more options than just "point" deployment of services. With Kubernetes Operators it should be possible to develop sophisticated compute engines that can deploy more complex sets of compute resources to be used for processing streams of data.
A framework that supports partitioning data and creating graphs of compute resources could provide the base structure for a compute engine that takes full advantage of containerization and what Kubernetes has to offer.
You may be asking why not have a large pool of K8's resources that can just grow as needed. The answer is type safety of data and shared nothing architecture. To truly have shared nothing architecture you need to keep compute resources partitions. With proper partitioning of resources and corresponding local positioning of data, you can get a type of "type safety for data" with the "type" being the snapshot version. This makes input data immutable during the processing of a set of calculations and this has benefits for synchronization between distributed nodes. See my earlier posts on all of that.
As per https://en.wikipedia.org/wiki/Shared-nothing_architecture
Nodes do not share (independently access) memory or storage. One alternative architecture is shared everything, in which requests are satisfied by arbitrary combinations of nodes
5/12/2020 addition
Watching the Tensorflow training on Coursera and they seem to have a similar concept of data.
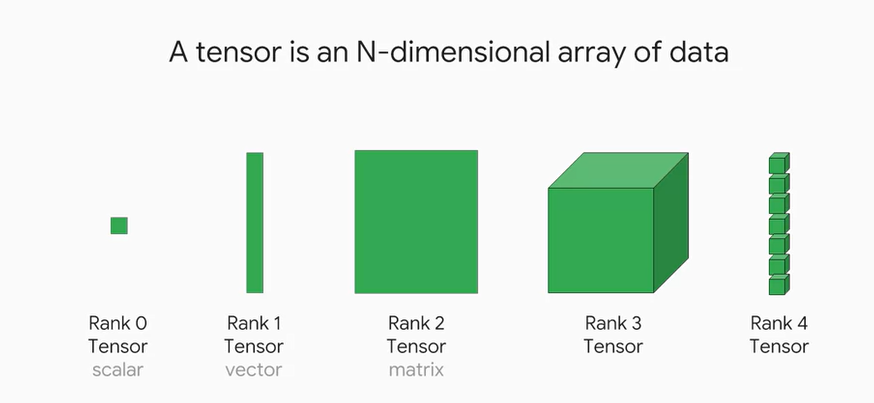
5/13/2020
What the multiverse of compute is saying is that not only is data multi-dimensional, but the compute fabric itself is multi-dimensional.
When you look at problems sets with a divide and conquer approach, you can see sections in a problem that can be broken out into pieces. These pieces form the compute fabric. The multi-dimensional aspect comes in when you realize that groups of pieces can be arranged in higher order fabrics.
This is what Kubernetes enables. The orchestration of this multi-dimensional compute fabric.
Why do this? It's shared nothing. Instead of 1 engine with many components (a complex fabric) processing 1000 pieces of data. 10 engines ? 100 engines? 1000 engines?
To make this happen the infrastructure level needs to support data flow at this level. It must know how to divide data up so that each of the engines gets its own set, and this must be done with data locality in mind; not one central data source, but maybe a data source per engine? Or maybe a data source for a subset of the engines? The goal is that compute should NOT have to query across the network for data. Data should be positioned as close as possible to the compute resource. This is what the Data DSL orchestrates; moving data next to the compute. This is not specific to one compute problem, it's something every compute problem must have; therefore it needs to be at the infrastructure level not embedded.
No comments:
Post a Comment