COMING SOON
File-based agent memory works — until you want cross-run lessons that stay auditable. We are expanding SDLC-SPDD Orchestrator with an optional context backend powered by Embabel Guide + Neo4j. Markdown stays canonical. Guide adds retrieval on top when you opt in.

Files first. Guide only when the marker is present and the service answers.
The idea
Today every /sdlc-spdd-* phase can already load context from indexes under agent-context/ and canvases under spdd/canvas/. That path stays the default forever.
The spike explores a DICE-style hybrid (Domain-Integrated Context Engineering): the same markdown the workflow already produces is projected into Guide twice — as RAG chunks and as typed domain entities — so the next session can ask not only “what text is similar?” but “what is connected to this Work ID or code area?”
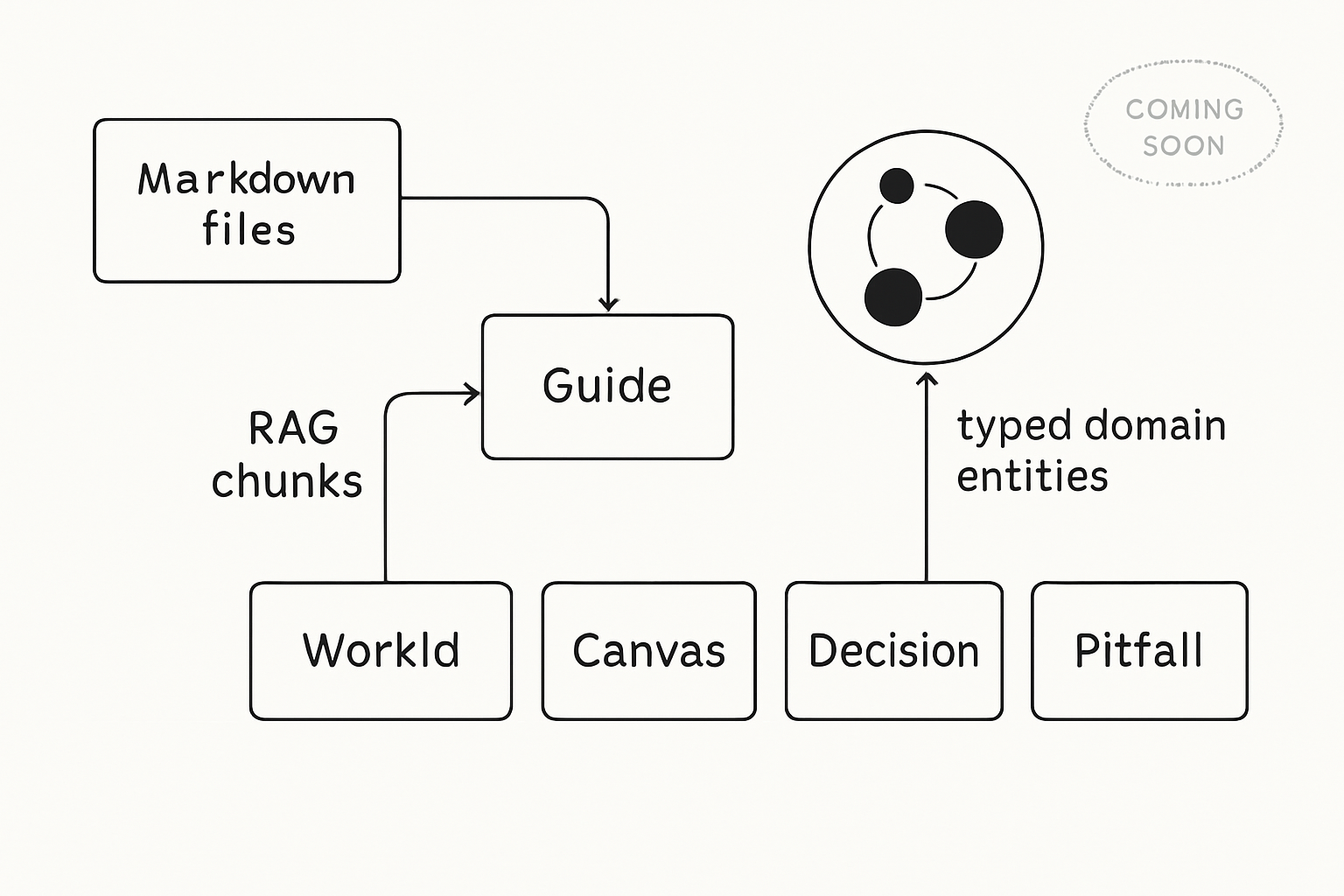
Dual ingest: chunks for discovery, entities + edges for explainable inclusion.
Three retrieval legs, one join key
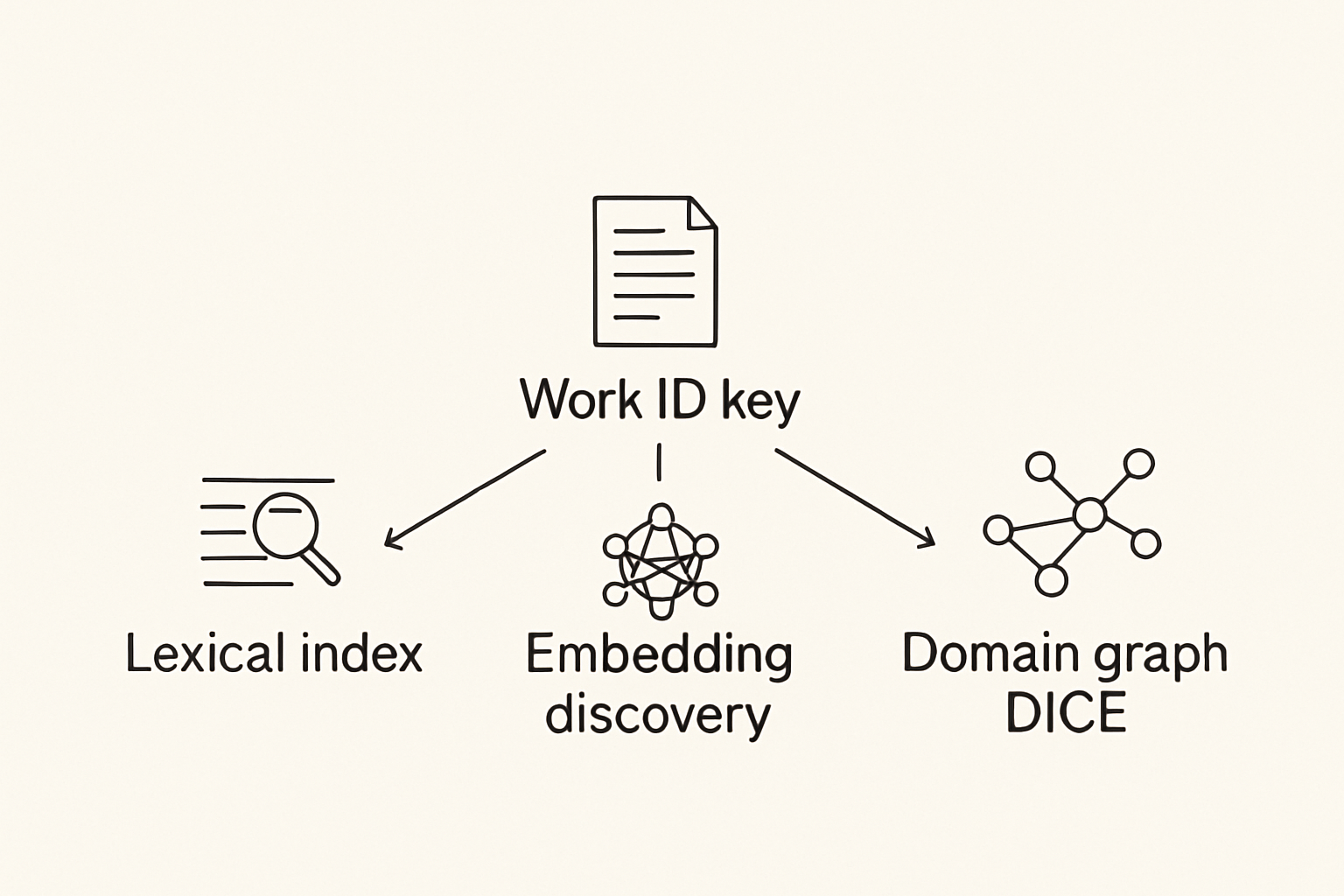
Work ID is the join key across lexical, embedding, and domain-graph legs.
- Lexical / area index — what you have today: deterministic, auditable, exact identifiers.
- Embedding discovery — Guide RAG (
docs_textSearch / docs_vectorSearch) to find entry points by paraphrase.
- Domain graph (DICE) — typed nodes such as WorkId, Canvas, Area, Decision, Pitfall, Pattern with edges (
canvas, area, decision, pitfall, pattern, about). Inclusion is justified by a link, not only a cosine score.
That last point matters for agent trust: when a prior pitfall from FEAT-001 shows up while coding FEAT-009 on the same area, you should be able to say why it was pulled in.
Optional at runtime — never assumed
Installs opt in with a marker (agent-context/harness/guide-dice.md via init-project.sh --with-guide). Every command still probes first:
- No marker →
CONTEXT_BACKEND=files (normal, not an error)
- Marker present but Guide down → same file fallback
- Guide live → augment analysis / architect / code / review with
spdd_* tools
No slash command may block because Guide is absent. That is a hard design rule of the spike.
How our work relates to the ideas we ingested
SDLC-SPDD did not start as a RAG project. It started as a way to run Fowler’s SPDD workflow under Troy’s context limits, with slash commands and file indexes. The Guide spike is the next question: can optional hybrid retrieval make that same workflow better at remembering across Work IDs without abandoning auditability?
While dogfooding SPIKE-001 we appended those authors (and a smaller secondary set) into a local Guide corpus — so retrieval experiments hit methodology prose and our canvases, not only our own markdown. Below is the mapping we actually use.
Fowler SPDD → our lifecycle (files today)
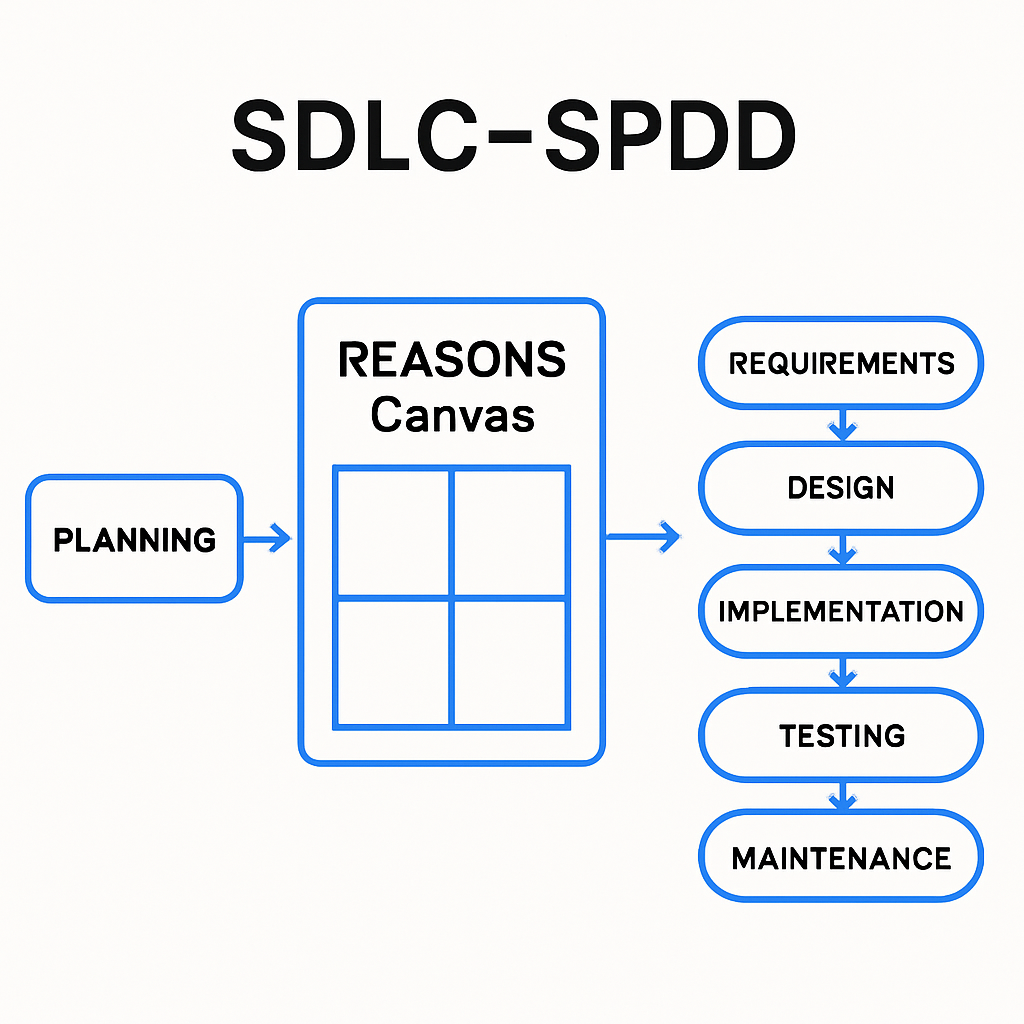
Structured-Prompt-Driven Development says prompts are delivery artifacts: versioned, reviewed, improved. Our response: every Work ID gets a REASONS canvas under spdd/canvas/; /sdlc-spdd-analysis then /sdlc-spdd-plan then /sdlc-spdd-architect before /sdlc-spdd-code; code implements one approved operation; /sdlc-spdd-review and /sdlc-spdd-sync close the loop. That is the same contract, made runnable in Cursor / Copilot / Claude (see also engineered.at on SPDD).
I still care about the code and the wider Exploring Gen AI series argue that AI does not excuse sloppy ownership of design and tests. Our response: behavior changes are prompt-first; the canvas stays the source of truth; API-test and review phases exist so “the model wrote it” is never the definition of done.
Harness engineering, Sensors for coding agents, and Pushing AI autonomy describe feedback loops and limits around agents. Our response: workflow CLI + pointer + readiness gates + the prompt-optimization ledger (FEAT-004/005) are our harness and sensors. We do not grant more autonomy until the canvas says Ready For Coding.
The craft ladder we dogfood — make it work → make it right → make it fast — sits in the same lineage as Beck’s make it run / make it right and Fowler on evolutionary design (Is Design Dead?, Refactoring). Guide is a make-it-fast spike: only after the file workflow is right.
How Guide extends Fowler in our spike: SPDD already persists decisions in markdown. Guide dual-ingest projects those same artifacts so the next Work ID can retrieve prior Operations / Decisions / Safeguards by graph link — still Fowler’s “improve the prompt artifacts over time,” but searchable across sessions without pasting every canvas into the chat.
Chelsea Troy → why our indexes exist (and what Guide must not break)
What can we expect of LLMs as software engineers? argues models are aides to a rigorous process, not a substitute for judgment — and that large dumps fail (“lost in the middle,” unscoped pastes). Fowler gives workflow; Troy explains why that workflow must stay narrow. We documented the mapping in Chelsea Troy and the framework.
| Troy’s point |
What we already ship |
What Guide must preserve |
| Don’t flood the context window |
Tiered grounding; context-index / domain-index / session rotation |
Retrieve a few linked lessons — never “all chunks similar to the prompt” |
| Work on cohesive slices |
/sdlc-spdd-analysis → domain keywords → code areas |
spdd_areaLessons keyed by area, not whole-repo RAG |
| Specific, testable problems |
REASONS Requirements / Operations; one op per /sdlc-spdd-code |
Surface pitfalls/decisions as Safeguards candidates — human still accepts |
| Judgment stays human |
Architect readiness, review-against-canvas, confidence-stack testing |
Optional backend; files fallback; no command fails if Guide is down |
| Don’t generate slop |
Governed canvases, sync logs, prompt-first behavior change |
Inclusions explained by typed edges, not opaque cosine alone |
Related Troy pieces we ingested for the same reason: Avoiding technical debt (process debt is still debt — our canvases fight that), On code coverage tools (satisficing sentinels → our quality gates), debugging tactics (investigation is delivery work — our analysis phase).
How Guide extends Troy in our spike: file indexes already narrow context. Guide’s domain graph is how we pull cross-Work-ID lessons for the same area without violating Troy — an about edge to scripts/ is a scoped slice, not a history dump. If retrieval cannot explain the inclusion, it fails our Troy test even if the embedding score looks good.
Rod Johnson / Embabel — why the Guide shape is DICE, not “more RAG”
Context engineering needs domain understanding argues typed domain objects should drive context. Agent memory is not a greenfield problem argues you should ground agents in data you already keep. Our response: we do not invent a parallel memory store. We project the SPDD domain we already have — WorkId, Canvas, Area, Decision, Pitfall, Pattern — into Neo4j __Entity__ with typed edges, and keep markdown canonical. Chunk RAG (legs 1–2) is for discovery; the graph (leg 3) is for “why is this in the prompt?”
Jasper Blues — the Guide we actually integrate with
Our spike talks to a real Embabel Guide instance (fork + projection APIs), not a toy RAG stub. Jasper Blues’ From Docs to Dialog is the product story behind that service: Hub’s “talk to the docs” guide built with Embabel, graph-backed RAG on Neo4j via Drivine, and Toolish RAG — the model gets search tools (docs_textSearch, docs_vectorSearch, broaden/zoom) instead of a single black-box retrieve step. How that relates to our work: when CONTEXT_BACKEND=guide-dice, analysis/architect/code phases call those same tool-shaped retrieval surfaces (plus our spdd_* graph tools). We are not inventing a second RAG stack; we are hanging SPDD domain projection off the Guide Jasper describes.
The (Very Slowly) Ticking Time-Bomb in Your Graph Persistence Stack explains why Drivine’s use-case-specific Cypher/projections matter for graph persistence. Our response: leg 3 is a deliberate projection of SPDD markdown into __Entity__ nodes and typed edges — not hoping directory ingest alone fills a domain graph. That matches Jasper’s “write the graph shape you need” stance and is why our fork work adds projection load + spdd_workSubgraph / spdd_areaLessons rather than only chunk ingest.
The Voice, The Word, and The Wheel shows Guide as an evolving product surface (narration agents, command loops, Toolish RAG for speech). We are not shipping voice in SPIKE-001 — but it reinforces that Guide is a living context backend with MCP/tool loops, which is exactly the runtime we probe with resolve-context-backend.sh. Those three Jasper/Embabel pieces are also in Guide’s default supplementary ingest list alongside Rod’s posts — the same corpus family we extend with Fowler/Troy for the spike.
Thread: Fowler/Troy define how we work in files. Rod’s DICE framing defines why typed memory. Jasper’s Guide writing defines the system we plug into — Toolish RAG + Drivine/Neo4j — so our coming-soon path is “SPDD domain on Guide,” not a greenfield memory product.
Secondary ingest — sensors for the experiment, not the product story
We also appended Anthropic’s notes on context engineering / long-running harnesses, 12-Factor Agents, Willison on LLMs for code, and Hamel/Yan on evals. How that relates to our work: they score the spike (context cost, eval discipline, harness thinking). They do not redefine the operating model — Fowler + Troy still do. Go/no-go asks whether Guide hybrid beats file indexes on the same Troy criteria Fowler’s workflow already assumes.
Status: coming soon
This work lives on spike branches and open PRs — it is not the default on main yet:
Much of the operator path is already dogfooded (ingest, projection, runtime probe, A/B spot-checks). The remaining gate is a formal go / no-go before anything becomes a recommended install option for adopters. Until then: treat it as preview, keep shipping file-based SDLC-SPDD on main, and watch this space.
What you can do today
- Use SDLC-SPDD with the file indexes — that path is production for the framework.
- Read the spike docs / PRs if you want the design early.
- Expect a follow-up post when go/no-go lands and the opt-in path is documented for adopters.
— John · github.com/jmjava/sdlc-spdd-orchestrator